Nå kan jeg umulig vite hva den eksakte årsaken er her, men det er en annen veldig god grunn, som ikke er nevnt så langt, for å bruke denne typen metoder: å kaste en demonter under statisk analyse.
Mekanikken til ring $ + 5 har blitt diskutert, så jeg antar at de er kjent nå - ellers referer til de andre svarene. I utgangspunktet som med alle samtaler på IA-32, blir returadressen (adressen til instruksjonen som følger samtalen ) push ed til stabelen og ret -instruksjonen inne i den ringte funksjonen vil antagelig gå tilbake til den adressen, forutsatt at bunken ikke har blitt knust i mellomtiden.
Lure statiske analyseverktøy
Hva vil til og med en sofistikert demonterer som IDA gjøre når den ser en ret opcode? Vel, det antar at funksjonsgrensen er nådd. Her er et eksempel:
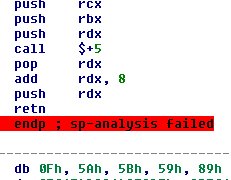
Nå som ikke dette er første gang jeg har sett noe slikt, fortsatte jeg og slettet funksjonen, så IDA slutter å anta at det er en funksjonsgrense. Hvis jeg da ber den om å demontere neste byte ( 0Fh ) får jeg dette:
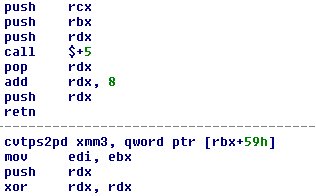
Hva demonteren ikke kan forstå og hva som er grunnen til at interaktive demontere som Hopper og IDA rocker så mye, er at det skjer noe spesielt her. La oss se på instruksjonene:
51 push rcx53 push rbx52 push rdxE8 00 00 00 00 call $ + 55A pop rdx48 83 C2 08 add rdx, 852 push rdxC3 retn0F 5A 5B 59 cvtps2pd xmm3, qword ptr [rbx + 59h] 89 DF mov edi, ebx52 push rdx
48 31 D2 xor rdx, rdx
De ledende byte er de faktiske byte i binær, etterfulgt av deres mnemoniske representasjon. Men vær spesielt oppmerksom på denne delen:
ring $ + 5pop rdx; <- = ADDRadd rdx, 8push rdxretn
Vi får adressen ADDR i rdx etter pop instruksjon ble utført. Vi vet dette mye fra beskrivelsen av mekanismen i de andre svarene. Men da blir det rart:
add rdx, 8
we add ... uhm eight bytes to that address ( ADDR + 8 ) og så skyver den til stabelen og kaller ret:
push rdxretn
Hvis du husker hvordan et -anrop fungerer, vil du huske at det skyver returadressen til stakken, og deretter overfører kjøringen til den ringte funksjonen, og den funksjonen kaller senere ret kode> for å gå tilbake til adressen som finnes på bunken. Denne kunnskapen blir utnyttet her. Den manipulerer "returadressen" før "returnerer" til den. Men når vi ser tilbake på demonteringen, finner vi til vår overraskelse (eller ikke;)):
E8 00 00 00 00 ring $ + 55A pop rdx48 83 C2 08 add rdx, 852 push rdxC3 retn0F 5A 5B 59 cvtps2pd xmm3, qword ptr [rbx + 59h]
La oss telle opcode-byte (i verktøyet ditt kan du også gjøre matte via forskyvninger, hvis du er så tilbøyelig):
5A48-
83 -
C2 -
08 -
52 -
C3 0F
Men vent litt, det betyr at vi bokstavelig talt overfører kjøring til midten av denne særegne cvtps2pd xmm3, qword ptr [rbx + 59h] ? Det er riktig. Fordi 0Fh er et av prefiksene som brukes ved koding av instruksjoner på IA-32. Så programmereren har lurt demonteren vår, men han vil ikke lure oss. Undefining av koden og deretter hopper over 0Fh prefikset vi får:
51 push rcx53 push rbx52 push rdxE8 00 00 00 00 call $ + 55A pop rdx48 83 C2 08 add rdx, 852 push rdxC3 retn0F db 0Fh5A pop rdx5B pop rbx59 pop rcx89 DF mov edi, ebx52 push rdx48 31 D2 xor rdx, rdx
eller:
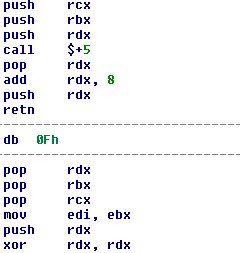
Den tilsynelatende enkle fire-byte-instruksjonen 0F 5A 5B 59 er nå avslørt å være falsk og i stedet vi må ignorere 0F og deretter fortsette ved 5A , som dekoder som pop rdx .
Sjekk ut Anges utmerkede opodetabeller her for å finne ut mer om hvordan instruksjonene blir kodet på IA-32.